
ModernBERT: A Leap Forward in Long-Context Language Models
Introduction
The field of Natural Language Processing (NLP) is constantly evolving, with new models and architectures pushing the boundaries of what's possible. One such recent advancement is ModernBERT, a modernized bidirectional encoder-only Transformer model that boasts impressive capabilities, particularly in handling long-context sequences. Developed through a collaboration between Answer.AI, LightOn, and other contributors, ModernBERT is poised to make a significant impact on various NLP tasks.
What is ModernBERT?
ModernBERT is a BERT-style model pre-trained on a massive 2 trillion tokens of English text and code data. What sets it apart from traditional BERT models is its ability to handle much longer context lengths, up to 8,192 tokens, thanks to its architectural improvements. This makes it suitable for tasks that require processing extensive documents, such as document retrieval, classification, and semantic search within large corpora.
Here are the key architectural improvements that contribute to ModernBERT's performance:
- Rotary Positional Embeddings (RoPE): Enables long-context support, allowing the model to effectively understand relationships between words even when they are far apart in a sequence.
- Local-Global Alternating Attention: Improves efficiency when processing long inputs by focusing on both local and global relationships within the text.
- Unpadding and Flash Attention: Optimizes inference for faster processing.
ModernBERT is available in two sizes:
- ModernBERT-base: 22 layers, 149 million parameters
- ModernBERT-large: 28 layers, 395 million parameters
How to Use ModernBERT
You can use ModernBERT directly with the transformers library from Hugging Face. As of now, you might need to install transformers from the main branch:
ModernBERT is a Masked Language Model (MLM), meaning you can use it with the fill-mask pipeline or load it via AutoModelForMaskedLM. Here's a quick example of using AutoModelForMaskedLM to predict a masked token:
For tasks like classification, retrieval, or QA, you can fine-tune ModernBERT following standard BERT fine-tuning procedures.
Important: To maximize efficiency, especially on GPUs that support it, you should use Flash Attention 2:
Performance and Evaluation
ModernBERT has been rigorously evaluated across a range of tasks, including:
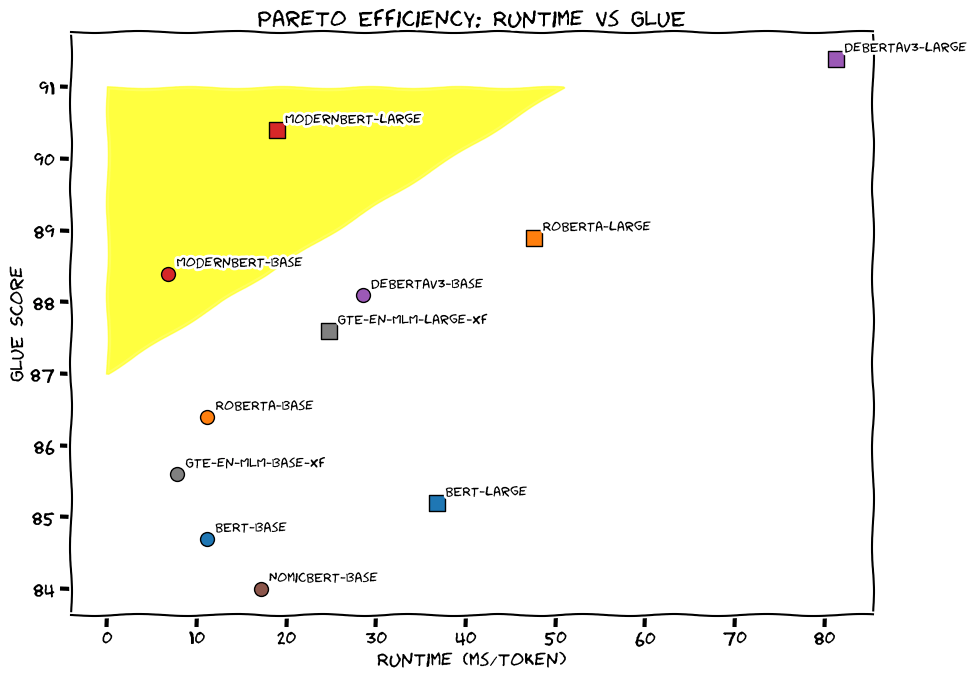
- Natural Language Understanding (GLUE): ModernBERT-base outperforms other similarly-sized encoder models, and ModernBERT-large comes in second only to Deberta-v3-large.
- General Retrieval (BEIR): ModernBERT performs exceptionally well in both single-vector (DPR-style) and multi-vector (ColBERT-style) settings.
- Long-Context Retrieval (MLDR): It shows strong performance in long-context retrieval tasks.
- Code Retrieval (CodeSearchNet and StackQA): Thanks to its pre-training on code data, ModernBERT achieves new state-of-the-art results in code retrieval.
Here's a summary of the performance highlights:
- ModernBERT consistently achieves top results across various tasks, often surpassing other comparable models.
- Its ability to handle long-context inputs efficiently makes it ideal for applications that require processing lengthy documents.
- The inclusion of code data in its training makes it a versatile model for both text and code-related tasks.
| Model | IR (DPR) | IR (ColBERT) | NLU | Code | Code |
|---|---|---|---|---|---|
| BEIR | BEIR | GLUE | CSN | SQA | |
| ModernBERT-base | 41.6 | 51.3 | 88.4 | 56.4 | 73.6 |
| ModernBERT-large | 44.0 | 52.4 | 90.4 | 59.5 | 83.9 |
Limitations
While ModernBERT is a powerful model, it's essential to be aware of its limitations:
- Language Bias: Primarily trained on English and code, its performance may be lower for other languages.
- Long Sequence Inference: Using the full 8,192 token window can be slower than short-context inference.
- Potential Biases: Like any large language model, it may reflect biases present in its training data.
Training Details
ModernBERT was trained using the following:
- Architecture: Encoder-only, Pre-Norm Transformer with GeGLU activations.
- Sequence Length: Pre-trained up to 1,024 tokens, then extended to 8,192 tokens.
- Data: 2 trillion tokens of English text and code.
- Optimizer: StableAdamW with trapezoidal LR scheduling and 1-sqrt decay.
- Hardware: Trained on 8x H100 GPUs.
Conclusion
ModernBERT represents a significant step forward in the world of NLP. Its ability to handle long-context sequences efficiently, coupled with its strong performance across various tasks, makes it a valuable tool for researchers and practitioners alike. If you're looking for a powerful, versatile encoder model, ModernBERT is definitely worth exploring.
For more in-depth information, refer to the release blog post and the arXiv pre-print.





