
ModernBERT: قفزة نوعية في نماذج اللغة ذات السياق الطويل
مقدمة
يتطور مجال معالجة اللغة الطبيعية (NLP) باستمرار، حيث تدفع النماذج والهندسات الجديدة حدود ما هو ممكن. أحد هذه التطورات الحديثة هو ModernBERT (ModernBERT)، وهو نموذج ترميز ثنائي الاتجاه محدث يتميز بقدرات مثيرة للإعجاب، خاصة في التعامل مع تسلسلات السياق الطويلة. تم تطوير ModernBERT من خلال تعاون بين Answer.AI وLightOn ومساهمين آخرين، وهو مهيأ لإحداث تأثير كبير على مهام معالجة اللغة الطبيعية المختلفة.
ما هو ModernBERT؟
ModernBERT هو نموذج على غرار BERT تم تدريبه مسبقًا على 2 تريليون رمز من بيانات النصوص والكود باللغة الإنجليزية. ما يميزه عن نماذج BERT التقليدية هو قدرته على التعامل مع أطوال سياق أطول بكثير، تصل إلى 8,192 رمز، وذلك بفضل تحسيناته الهيكلية. هذا يجعله مناسبًا للمهام التي تتطلب معالجة وثائق مطولة، مثل استرجاع المستندات وتصنيفها والبحث الدلالي داخل مجموعات كبيرة من النصوص.
فيما يلي التحسينات الهيكلية الرئيسية التي تساهم في أداء ModernBERT:
- تضمينات موضعية دورانية (RoPE): تمكّن من دعم السياق الطويل، مما يسمح للنموذج بفهم العلاقات بين الكلمات بشكل فعال حتى عندما تكون بعيدة عن بعضها في التسلسل.
- انتباه متناوب محلي-عالمي: يحسن الكفاءة عند معالجة المدخلات الطويلة من خلال التركيز على العلاقات المحلية والعالمية داخل النص.
- إزالة الحشو والانتباه السريع (Flash Attention): يحسن عملية الاستدلال لمعالجة أسرع.
يتوفر ModernBERT بحجمين:
- ModernBERT-أساسي: 22 طبقة، 149 مليون معلمة
- ModernBERT-كبير: 28 طبقة، 395 مليون معلمة
كيفية استخدام ModernBERT
يمكنك استخدام ModernBERT مباشرة مع مكتبة transformers من Hugging Face. حاليًا، قد تحتاج إلى تثبيت transformers من الفرع الرئيسي:
1pip install git+https://github.com/huggingface/transformers.git
ModernBERT هو نموذج لغة مقنع (MLM)، مما يعني أنه يمكنك استخدامه مع خط أنابيب fill-mask أو تحميله عبر AutoModelForMaskedLM. إليك مثالاً سريعًا لاستخدام AutoModelForMaskedLM للتنبؤ برمز مقنّع:
1from transformers import AutoTokenizer, AutoModelForMaskedLM23model_id = "answerdotai/ModernBERT-base"4tokenizer = AutoTokenizer.from_pretrained(model_id)5model = AutoModelForMaskedLM.from_pretrained(model_id)67text = "The capital of France is [MASK]."8inputs = tokenizer(text, return_tensors="pt")9outputs = model(**inputs)1011# To get predictions for the mask:12masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)13predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)14predicted_token = tokenizer.decode(predicted_token_id)15print("Predicted token:", predicted_token)16# Predicted token: Paris
لمهام مثل التصنيف أو الاسترجاع أو الأسئلة والأجوبة، يمكنك ضبط ModernBERT باتباع إجراءات ضبط BERT القياسية.
هام: لتحقيق أقصى قدر من الكفاءة، خاصة على وحدات معالجة الرسومات التي تدعمها، يجب عليك استخدام الانتباه السريع 2:
1pip install flash-attn
الأداء والتقييم
تم تقييم ModernBERT بدقة عبر مجموعة من المهام، بما في ذلك:
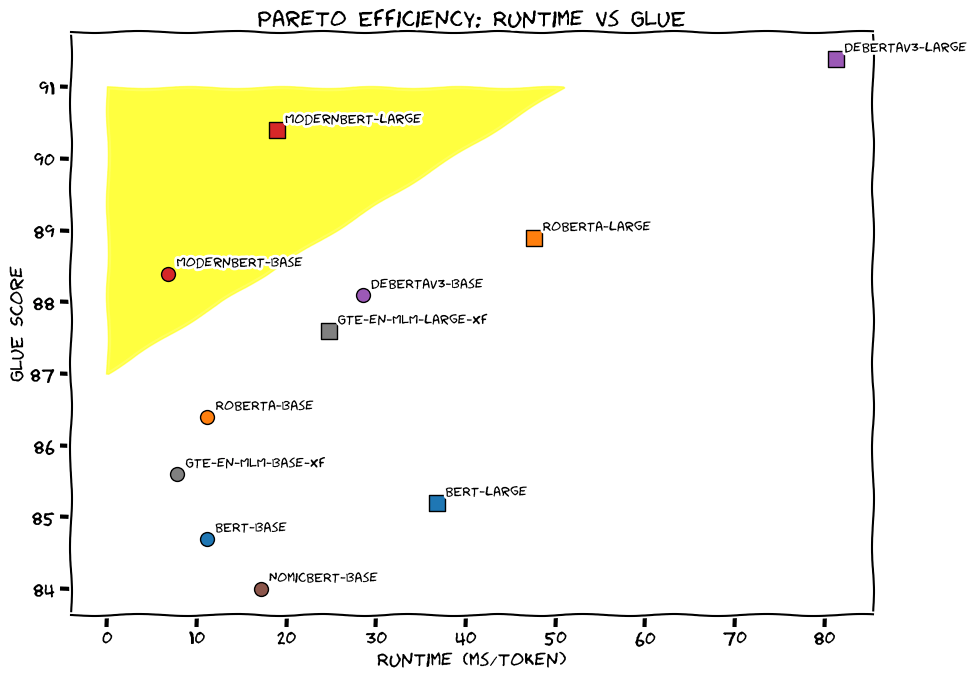
- فهم اللغة الطبيعية (GLUE): يتفوق ModernBERT-الأساسي على النماذج الأخرى ذات الحجم المماثل، ويأتي ModernBERT-الكبير في المرتبة الثانية بعد Deberta-v3-large فقط.
- الاسترجاع العام (BEIR): يقدم ModernBERT أداءً استثنائيًا في إعدادات المتجه الفردي (على غرار DPR) والمتجهات المتعددة (على غرار ColBERT).
- استرجاع السياق الطويل (MLDR): يُظهر أداءً قويًا في مهام استرجاع السياق الطويل.
- استرجاع الكود (CodeSearchNet و StackQA): بفضل تدريبه المسبق على بيانات الكود، يحقق ModernBERT نتائج جديدة تمثل أفضل ما توصل إليه العلم في مجال استرجاع الكود.
فيما يلي ملخص لأبرز نقاط الأداء:
- يحقق ModernBERT باستمرار نتائج رائدة عبر مهام متنوعة، متفوقًا في كثير من الأحيان على النماذج الأخرى المماثلة.
- قدرته على التعامل مع المدخلات ذات السياق الطويل بكفاءة تجعله مثاليًا للتطبيقات التي تتطلب معالجة مستندات طويلة.
- تضمين بيانات الكود في تدريبه يجعله نموذجًا متعدد الاستخدامات لكل من المهام المتعلقة بالنص والكود.
| النموذج | IR (DPR) | IR (ColBERT) | NLU | Code | Code |
|---|---|---|---|---|---|
| BEIR | BEIR | GLUE | CSN | SQA | |
| ModernBERT-أساسي | 41.6 | 51.3 | 88.4 | 56.4 | 73.6 |
| ModernBERT-كبير | 44.0 | 52.4 | 90.4 | 59.5 | 83.9 |
القيود
على الرغم من أن ModernBERT هو نموذج قوي، من الضروري أن تكون على دراية بحدوده:
- التحيز اللغوي: تم تدريبه بشكل أساسي على اللغة الإنجليزية والكود، لذا قد يكون أداؤه أقل بالنسبة للغات الأخرى.
- استدلال التسلسل الطويل: استخدام النافذة الكاملة 8,192 رمز قد يكون أبطأ من استدلال السياق القصير.
- التحيزات المحتملة: مثل أي نموذج لغة كبير، قد يعكس التحيزات الموجودة في بيانات تدريبه.
تفاصيل التدريب
تم تدريب ModernBERT باستخدام ما يلي:
- الهندسة: محول معياري مسبق للترميز فقط مع تنشيطات GeGLU.
- طول التسلسل: تم تدريبه مسبقًا حتى 1,024 رمز، ثم تم تمديده إلى 8,192 رمز.
- البيانات: 2 تريليون رمز من النصوص والكود باللغة الإنجليزية.
- المحسن: StableAdamW مع جدولة LR شبه منحرفة وتناقص 1-sqrt.
- الأجهزة: تم تدريبه على 8 وحدات معالجة رسومات H100.
الخلاصة
يمثل ModernBERT خطوة مهمة إلى الأمام في عالم معالجة اللغة الطبيعية. إن قدرته على التعامل مع تسلسلات السياق الطويل بكفاءة، إلى جانب أدائه القوي عبر مهام مختلفة، تجعله أداة قيمة للباحثين والممارسين على حد سواء. إذا كنت تبحث عن نموذج ترميز قوي ومتعدد الاستخدامات، فإن ModernBERT يستحق بالتأكيد الاستكشاف.
للمزيد من المعلومات المتعمقة، راجع منشور الإصدار والمطبوعة المسبقة على arXiv.





